Predicting Responses to Psychological Questionnaires from Participants’ Social Media Posts and Question Text Embeddings
Abstract
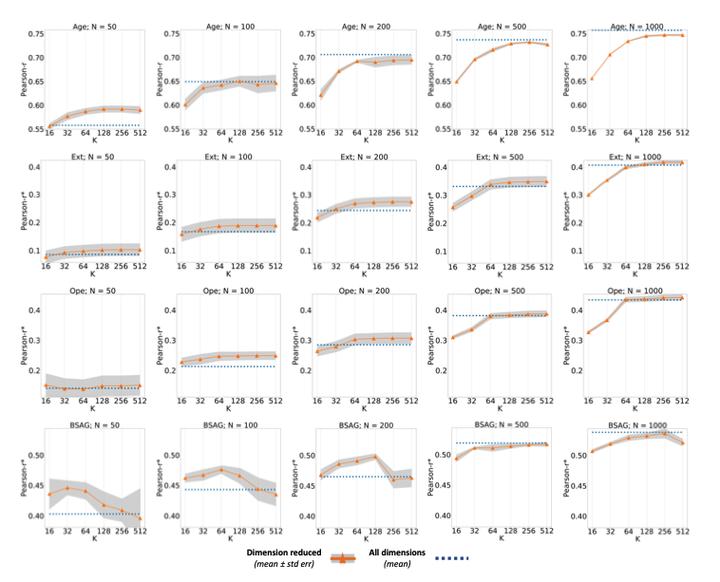
In human-level NLP tasks, such as predicting mental health, personality, or demographics, the number of observations is often smaller than the standard 768+ hidden state sizes of each layer within modern transformer-based language models, limiting the ability to effectively leverage transformers. Here, we provide a systematic study on the role of dimension reduction methods (principal components analysis, factorization techniques, or multi-layer auto-encoders) as well as the dimensionality of embedding vectors and sample sizes as a function of predictive performance. We first find that fine-tuning large models with a limited amount of data pose a significant difficulty which can be overcome with a pre-trained dimension reduction regime. RoBERTa consistently achieves top performance in human-level tasks, with PCA giving benefit over other reduction methods in better handling users that write longer texts. Finally, we observe that a majority of the tasks achieve results comparable to the best performance with just 1/12 of the embedding dimensions.